[toc]
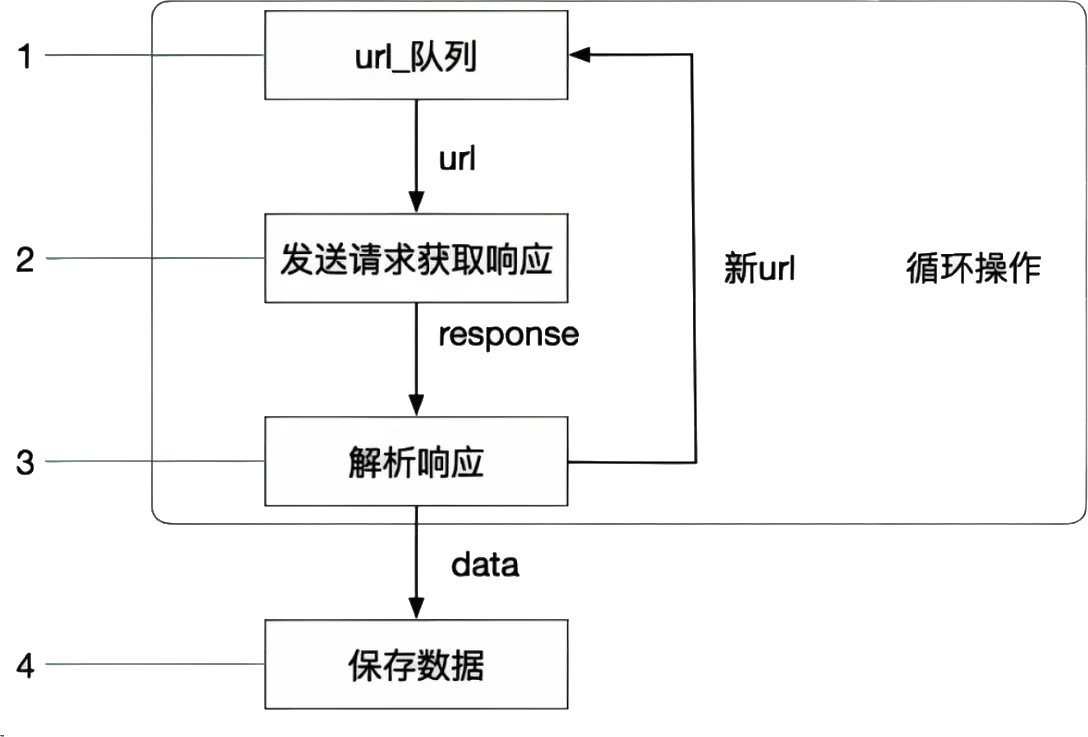
从根页面获取链接
打开源代码,Ctrl U观察源代码中是否有要获取的内容
有直接爬取
获取源代码
再看一看获得源代码里有无要获取的内容,有说明爬取没问题
找到要获取元素的上上上级标签,最好是<li>,代码中空格用.*?来代替,中间一帮子不知道啥玩意也用这个代替
数据获取
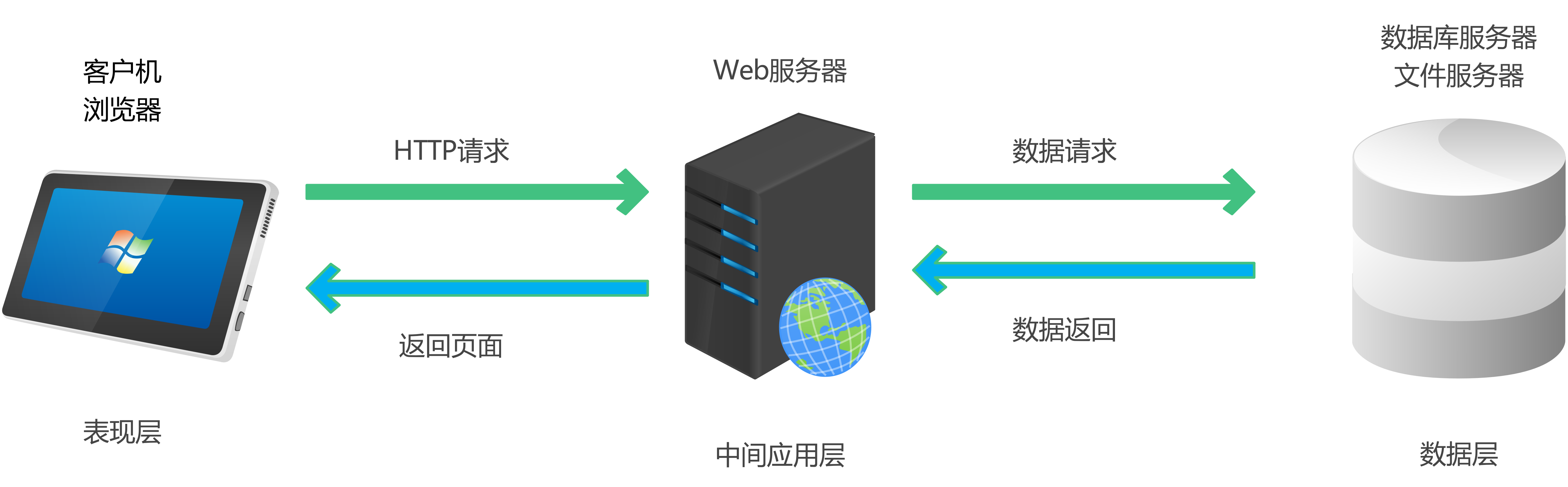
浏览器访问网页,是先向目标Web服务器发送HTTP请求,然后接收并解析服务器返回的数据。
因此想要爬取网页中的数据,首先得先构造HTTP请求并发送给Web服务器,并接收返回响应数据。一般使用requests模块处理HTTP的各种请求。
发送请求
GET 和 POST 是 HTTP 协议中最核心的两种请求方法,GET 请求可以通过字符串在URL中体现,POST 请求的具体数据隐藏在请求体中。
response = requests.get(url, headers=header) # 发送请求
if response.status_code == 200: # 判断是否返回正常响应
print("请求成功")
else:
print("请求失败,状态码:", response.status_code)
response.close() # 访问完随时关闭请求GET 请求
response = requests.get(url)- url:请求地址
headers:请求头,字典格式params:参数,格式是字典
POST 请求
response = requests.post(url, data)data:以POST请求发送数据,格式是字典
请求返回的是Response 对象。
Response 对象
Response 对象即服务器对客户端请求的封装响应,其包含了服务器返回给客户端的所有信息,包括响应体、响应头等。
响应体
在浏览器与服务器交互时,服务器返回的响应通常由响应头和响应体组成,响应体就是服务器返回的实际数据。
| 函数 | 含义 |
|---|---|
response.text |
以字符串形式返回服务器响应 |
response.content |
以字节形式返回服务器响应<br / >(可以获取网页中的图片、文件等二进制数据) |
response.json() |
将响应内容解析为JSON格式 |
响应头
在HTTP协议中,响应头包含了关于报文的元数据,尤其是可以通过状态码判断是否响应成功。
| 函数 | 含义 |
|---|---|
response.status_code |
状态码 |
response.request.headers |
请求报文头部 |
response.headers |
响应报文头部 |
response.request._cookies |
请求报文 Cookie |
response.cookies |
响应报文 Cookie |
数据解析
通过requests模块获得的网页请求,包含了整个网页文件的内容。纷繁复杂,啥都有。因此需要对网页文件进行解析,获取想要的内容后再进行进一步的处理。
正则表达式
详见《正则表达式》。
Python中的正则
Python中使用re模块撰写正则表达式。
| 方法名 | 语法 | 含义 |
|---|---|---|
findall |
re.findall(r'正则', '字符串') |
匹配字符串所有内容,以表格格式返回 |
finiter |
re.finditer(r'正则', '字符串') |
匹配字符串所有内容,以迭代器格式返回更高效 用 .group()函数获取迭代内容的具体数据 |
search |
re.search(r'正则', '字符串') |
匹配字符串的首个匹配内容,以match对象返回用 .group()获取数据没有返回 None |
match |
re.match(r'正则', '字符串') |
默认字符串开头就要匹配 |
compile |
re.compile(r'正则') |
预加载表达式,将正则表达式封装成一个对象,查询时可以直接调用 |
爬虫时使用正则
obj = re.compile(r"<div class='.*?'>(?P<分组名>.*?)</div>", re.S) # 撰写正则规则
# re.S 让.能匹配换行符
# (?P<分组名>正则) 可以从正则匹配内容中进一步提取内容
result = obj.finditer(s) # 匹配所有结果
for it in result:
it.group("id") # 获取组里的内容BeautifulSoup
BS4就是根据标签的属性去查找,和CSS查找器差不多。
首先要将页面源代码生成 bs 对象。
page = bs4.BeautifulSoup(resp.text, "html.parser")从 bs 对象中查找数据
| 语法 | 含义 |
|---|---|
page.find("标签名", 属性="值") |
找首个属性值的标签 如果属性是关键字,就用 属性_ |
page.find("标签名", attrs={"属性": "值"}) |
找首个属性值的标签 |
page.find_all("标签名", 属性=值) |
找到所有标签 以列表形式给出 |
通过BS4拿到标签后,可以用.text表示标签中内容,通过.get("属性")获取标签的属性值。
XPath
XPath是一种用于在 XML 或 HTML 文档中定位和选择节点的查询语言,其提供了非常简洁明了的路径选择表达式,另外它还提供了超过 100 个内建函数用于字符串、数值、时间的匹配以及节点、序列的处理等等,几乎所有我们想要定位的节点都可以用XPath来选择。
| 表达式 | 描述 |
|---|---|
nodename |
选取节点所有子节点 |
/ |
根节点 |
// |
从匹配选择的当前节点 |
. |
当前节点 |
.. |
当前节点父节点 |
@属性名 |
选取属性 |
text() |
获取文本 |
| 表达式 | 描述 |
|---|---|
/标签1/标签2[n] |
标签1子元素中第 n 个标签2 |
/标签1/标签2[last()-(n-1)] |
标签1子元素中倒数第 n 个标签2 |
/标签1/标签2[position() < n] |
标签1子元素中前 n 个标签2 |
//标签1[@属性1] |
选取拥有属性1的全部标签1 |
//标签1[@属性1=x] |
选取拥有属性1为x的全部标签1 |
* |
通配符 |
from lxml import etree
page = response.content.decode()
# 将HTML内容转换为xml文档对象
html = etree.HTML()
# 也可以直接读取 html 文件
html = etree.parse("文件路径.html")
title = html.xpath("表达式")- 定位到包含数据所有元素
- 找到包含具体内容的子元素
- 对子元素遍历,提取详细内容
反爬
请求头
- User-Agent
- 防盗链接——检测请求来源(请求头中Refer属性,即打开请求前在哪个页面)
Max retries exceeded with url
request.get(url, verify=False) 去掉安全验证
编码不一样
request编码默认UTF-8
从<meta>中获取编码
resp.encoding = ‘’
模拟浏览器登陆
通过代码模拟人工请求登录,然后访问数据
通过抓包,找到登录接口
打开目标网页,点击登录
打开F12,随便输入账号密码
查看控制台登录请求中的url地址和请求参数
分辨鉴权方式
- cookie + session
- token
编码传入正确账号和密码
使用 cookie + session 模拟登陆
- 传账号密码登录
- 登录后保存cookie(返回报文头的 set-cookie)
- 请求其他页面时携带cookie
# 1
login_url = "..."
params = {
"username": "...",
"password": "..."
}
response = requests.post(url,headers , data=params)
# 2 获取cookies
cookies = response.cookies
# 2.1
request.post(url, cookies=cookies)
#2.2
headers = {
'Cookie': "..."
}
# 2.3 自动保留cookie,最常用
http = requests.session() # 创建请求对象
response = http.post(url, data)使用 token 模拟登录
- 传递账号密码登录
- 登录后保存token(响应报文响应体
- 请求其他页面携带token
鉴权
cookie
session
token
防盗链
很多页面内容不是直接显示在html中的,是后续ajax异步请求拿到的
在 F12 网络里找到对应cont
根据F12返回内容拿到url
对url进行修改
下载
refer
代理——
防止封 IP
通过第三方机器发送请求
proxies = {
"https": "https://xx.xx.xx.xx:xxxx"
}
request.get(url, proxies)Cookie池
多线程
async def download(url):
async def download(url):
# 发送请求
# 得到文件内容
# 保存到文件
async with aiohttp.ClientSession() as session: # request
async with session.get(url) as resp: resp = request.get()
with open(name, mode='wb') as f:
f.write(await resp.content.read())
async def main():
urls = []
tasks = []
for url in urls:
d = download(url)
tasks.append(asyncio.create_task(d))
请求
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())多线程
多进程
协程
爬视频
M3U8
- 找到m3u8
- 通过m3u8下载ts文件
- 合并成mp4
Selenium
模仿人自动化操作页面
打开浏览器
driver = selenium.webdriver.Chrome()操作页面
driver.get(url)获取页面数据
html = driver.page_source
current_url:当前 urltitle:页面标题page_source:页面 html 代码window_handler:获取浏览器所有窗口句柄current_window_handle:获取当前窗口句柄
元素定位
通过 id 查找
element = driver.find_element_by_id("id值")**通过 name 定位 **
element = driver.find_element_by_name("")**通过 class 定位 **
driver.find_element_by_class_name("").通过xpath定位
ele = driver.find_element(By.XPATH, 'xPath值')元素属性
tagname:标签名text:标签文本parent:父标签get_attribute():获取属性s_displayed():判断元素是否可见click():点击元素send_keys():输入内容clear():清空表单
隐氏等待
页面加载出来就会继续执行,否则
driver.implicitly_wait(值);
嵌套网页
<iframe>
切换到指定 iframe
# 1 driver.switch_to.frame(值)值可以是 iframe 的name属性,也可以是通过xpath查找的对象
切换回默认页面
driver.switch_to.default_content()切换到父级iframe
driver.switch_to_parent_frame()
鼠标操作
from selenium webdriver import ActionChains
ac = ActionChains(driver)click:鼠标左击double_click:双击context_click:右击move_to_element:移动到某个节点click_and_hold:按住左键move_by_offse:相对当前位置进行移动drag_and_drop:在一个位置按下,到另一个位置释放release():释放鼠标perform():执行上述操作
反Selenium
- User-Agent
- 请求头有自动化标识
- window对象会有特定属性
- 页面加载行为
--disable-infobars:禁止Chrome显示自动化测试通知栏excludeSwitches、enable-automation:排除启动自动化程序开关useAutomationExtension: False“禁用自动化扩展Page.addScriptToEvaluateOnNewDocument:在每次页面加载执行JS代码,隐藏生成的属性
# 添加参数
opt = webdriver.ChromeOptions()
opt.add_argument('--disableinfobars')
opt.add_experimental_option("excludeSwitches", ["enable-automation"])
opt.add_experimental_option('useAutomationExtension', False)
driver = selenium.webdriver.Chrome(option=opt)
# 在打开页面前,运行JS
with open('hide.js') as f:
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": f.read()})
找加密
查找到输入参数后调用参数生成的函数
输入不同参数看看生成出的不同结果
调试到函数
反调试
禁用F12
先开F12,再进页面
检测调试工具
定时检测
function Debugging() { debugger setInterval(Debugging, 1000) }清空控制台
function startClearConsole() { setInterval(function () { console.clear()l; }, 1000); }
var debugflag = false;
endebug(false, function () {
document.write('检测到非法调试, 请关闭调试终端后刷新本页面重试!');
document.write("<br/>");
document.write("Welcome for People, Not Welcome for Machine!");
debugflag = true;
});
txsdefwsw();
document.onkeydown = function() {
if ((e.ctrlKey) && (e.keyCode == 83)) {
alert("检测到非法调试,CTRL + S被管理员禁用");
return false;
}
}
document.onkeydown = function() {
var e = window.event || arguments[0];
if (e.keyCode == 123) {
alert("检测到非法调试,F12被管理员禁用");
return false;
}
}
document.oncontextmenu = function() {
alert('检测到非法调试,右键被管理员禁用');
return false;
}
$(function()
{
if (!debugflag && !window.navigator.webdriver) {
loadTab();
}
if(!isSupportCanvas())
{
$("#browertip").show();
}
});
function isSupportCanvas()
{
var elem = document.createElement('canvas');
return !!(elem.getContext && elem.getContext('2d'));
}// 检测调试器是否开始
function endebug(off, code) {
if (!off) {
!function(e) {
function n(e) {
function n() {
return u
}
function o() {
window.Firebug && window.Firebug.chrome && window.Firebug.chrome.isInitialized ? t("on") : (a = "off",
console.log(d),
console.clear(),
t(a))
}
function t(e) {
u !== e && (u = e,
"function" == typeof c.onchange && c.onchange(e))
}
function r() {
l || (l = !0,
window.removeEventListener("resize", o),
clearInterval(f))
}
"function" == typeof e && (e = {
onchange: e
});
var i = (e = e || {}).delay || 500
, c = {};
c.onchange = e.onchange;
var a, d = new Image;
d.__defineGetter__("id", function() {
a = "on"
});
var u = "unknown";
c.getStatus = n;
var f = setInterval(o, i);
window.addEventListener("resize", o);
var l;
return c.free = r,
c
}
var o = o || {};
o.create = n,
"function" == typeof define ? (define.amd || define.cmd) && define(function() {
return o
}) : "undefined" != typeof module && module.exports ? module.exports = o : window.jdetects = o
}(),
jdetects.create(function(e) {
var a = 0;
var n = setInterval(function() {
if ("on" == e) {
setTimeout(function() {
if (a == 0) {
a = 1;
setTimeout(code)
}
}, 200)
}
}, 100)
})
}
}
写油猴脚本新函数覆盖掉?
图形验证码
import ddddocr
ocr = ddddocr.DdddOcr()
code = ocr.classification(img)字体反爬
自己整了个字体,导致F12乱码
还是用OCR



