这是阅读论文《A GPU-based machine learning approach for detection of botnet attacks》读书笔记
研究背景
物联网僵尸网络
不法分子旨在通过设备互联构成一个大型网络传播恶意软件。僵尸网络即由恶意软件感染的各种物联网设备集合,其力量大小(作用范围)取决于组成它的设备数量
僵尸网络架构
集中式网络
所有设备都连接到 C&C命令和控制服务器,自动化命令通过 IRC 或 HTTP 通道从 C&C 发送到设备
优点:直接通信,延迟低
缺点:依赖于 C&C,因此 C&C 一旦被发现则有被控制设备信息都会显露
分布式网络
没有故障中心点,不可能因为某一点暴露而崩盘,使用 P2P 通信协议连接
混合式网络
折衷集中式网络和分布式网络,使得通信低延迟同时能用 P2P 通信保护整个僵尸网免于检测
恶意软件攻击方式
攻击方式
- 早期:利用默认密码或弱密码攻击设备
- 当前:利用弱Telnet密码和三个漏洞进行传播通过Tor代理功能提供IP服务器地址
对抗策略
即时检测僵尸网络的存在,提高设备抵御攻击的能力,最终限制僵尸网络资源
对抗工具
IDS:用于监测网络流量和检测入侵信号的系统
检测方法
基于签名的方法
通过查看给定威胁的特定模式和签名来检测恶意数据包,根据可执行恶意软件的签名或其生成的恶意网络流量的签名进行检测
主要问题:需要频繁更新入侵者数据库,且无法识别未知攻击
基于异常的方法
学习值得信任的签名和行为,并基于这些知识仅让合法流量通过。如果IDS在分析的流量中发现异常,则会标记这一数据包。
主要问题:由于算法还未学习新的合法流量,所以对于新的合法流量也会进行标记,造成越来越多的假阳性警报
研究重点:保持可接受检测水平的同时提高检测速度
相关技术
技术背景
机器学习算法:机器学习算法以历史数据预测新数据,可以监视系统并对行为变化做出及时反应,通过模式检测、实时威胁监视、漏洞映射和渗透测试等方法来防止威胁
网络攻击特点:入侵者(威胁者)行为无法预测。攻击者的行为均是隐匿的,且由不同攻击者执行的相同攻击看起来完全不同。因此许多机器学习模型必须适应不同的条件和行为参数,无法得到广泛使用
评价指标缺点:大多数解决流量监测的方法仅关注准确性而忽略了训练和预测时间
工作总结
尽管 SVM 准确率很高,但集成学习算法随机森林比 SVM 执行更好。随机森林准确率更高、训练时间更短、预测速度更快。而训练时间和预测速度在行业使用中很重要,因为为了跟进最新的威胁,用于 IoT 的机器学习模型必须定期更新。更短的训练时间和更快的预测速度意味着更早更及时的更新和部署。
实验
实验方法
- 从公共存储库获取数据集并对包含足够信息的较小集合进行采样以训练机器学习模型
- 将数据拆分为适当的集,以进行模型训练和评估
- 对部分数据应用过采样技术(oversampling)
- 在特征工程过程中派生一组新特征(重点)
- 对所有特征进行选择凝练出更小的最佳特征集用于模型训练
- 模型超参数设置、再训练和评估,直至结果令人满意
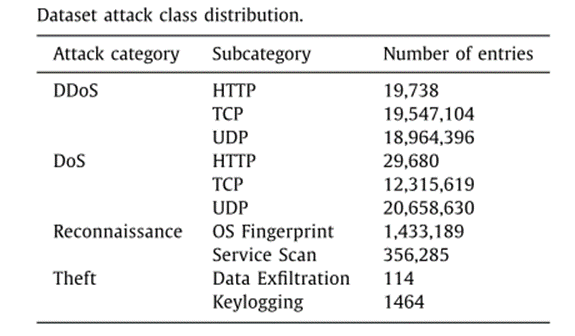
数据集
来自UNSW Canberra at ADFA的IDS数据集的最新一轮迭代——BoT-IoT数据集
特征选择
使用置换重要性方法(Permutation Importance)移除对算法预测能力无影响的特征
原理:置换特征重要性会反映出重要性最低的特征
做法:对导致模型得分下降的特征值随机变换破坏特征与目标之间联系从而反映出模型对特定特征的依赖程度
类分布
本实验采用最为广泛使用的过采样方法——合成少数类过采样技术消除数据集类分布不均匀偏差
类不均匀分布是机器学习常见问题,很难找到完全均匀数据集。针对类分布不均匀问题由两种解决方案:
- 过采样:复制数量不足的类(次类)样本实例,建议在小数据集上使用过采样
- 欠采样:删除数量过多的类(主类)样本实例,建议再大数据集上使用欠采样大数据集中样本实例的删除不会对模型产生较大影响
算法及实验流程
随机森林、SVM、逻辑回归、K 近邻。本实验采用 cuML 库中 GPU 加速版本的各分类器。
优点:GPU 加速版本训练预测时间较短只能利用CPU
缺点:GPU加速算法仍在开发中,功能受限RAPIDS算法默认设置比Scikit-learn差,必须进行超参数优化
评价指标
TP:模型正确预测正类的数目
TN:模型正确预测负类的数目
FP:模型错误预测正类的数目
FN:模型错误预测负类的数目
$Accuracy=\dfrac{TP+TN}{TP+TN+FP+FN}$
$Precision=\dfrac{TP}{TP+FP}$
$Recall=\dfrac{TP}{TP+FN}$
$F-Score=\dfrac{2\times Precision\times Recall}{Precision+Recall}$
研究结果
- KNN:算法训练时间最短但预测时间长,因为其不会预先概括数据
- LR:训练时间最短但准确性和鲁棒性太低,无法使用
- SVM:训练时间最长,因而对IDS来说不可行,IDS必须经常重新训练以应对最新威胁
- RF:虽然时间指标不是最佳,但总体而言是最佳算法,能够在合理的训练和预测时间条件下给出最佳预测



