本文为论文《Incorporating deep learning into capacitive images for smartphone user authentication》读书笔记。
研究背景
智能手机安全上,被建议使用生物识别技术验证身份,但目前智能设备中使用的物理生物识别技术还存在安全性和可用性问题。而目前所有智能手机都包含电容式触屏技术,作为电阻式触屏技术的替代品,可以捕捉身体指纹,如四根手指、耳朵和拇指的生物特征。
相关技术
电容帧提取
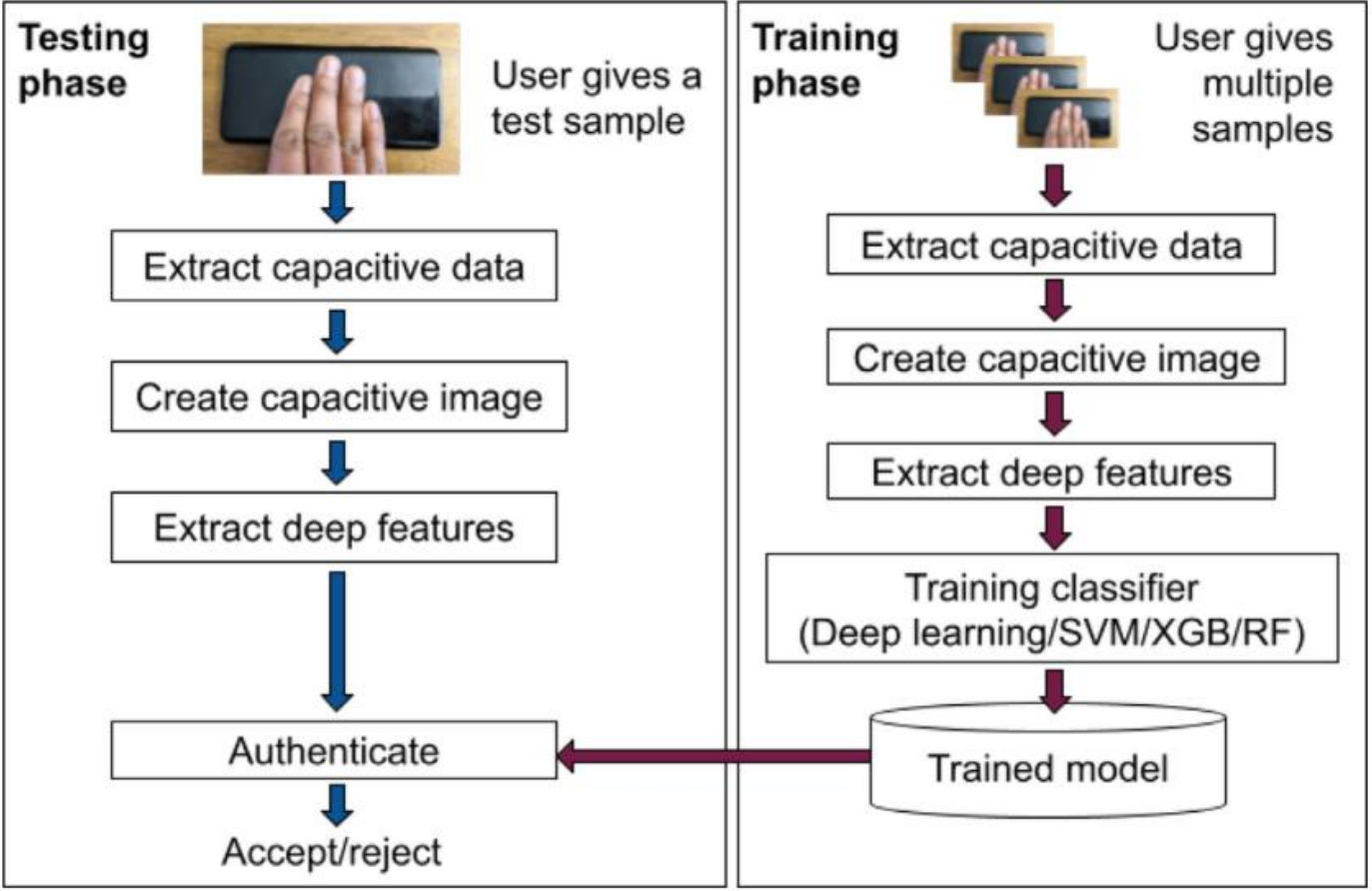
用户将身体部位四个手指、耳朵、拇指放在屏幕,从触摸控制器提取许多电容帧。从15×27灰度图像身体部位,提取部位图像通常为矩形,大小各异。使用以下公式将提取身体部位图像调整为 10×10 图像:
$$
Q\left(x^q,y^q\right)=P\left(x^l+\dfrac{x^h-x^l}{10}x^q,\dfrac{y^h-y^l}{10}y^q\right)
$$
生物识别评价标准
误识率 FAR:本该匹配错误但识别为正确的比例
$$
FAR=\dfrac{NFA}{NIRA}\times 100%
$$- NIRA——类间匹配总次数
- NFA ——错误接受的次数
拒识率 FRR:本该匹配正确但识别为错误的比例
$$
FAR=\dfrac{NFR}{NGRA}\times 100%
$$
NFR ——错误拒绝的次数等错误率 ERR:FAR 和 FRR 两条曲线的交点,对应的那个阈值
等错误率值越低,生物识别系统的准确度越高
受试者工作特征曲线 ROC曲线:
以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线
ROC 曲线的评价方法与传统的评价方法不同,无须此限制,而是根据实际情况,允许有中间状态
关键技术
UASNet
UASNet 是一种 CNN,基于 DenseNet-121、ResNet-34 架构。UASNet 有三个分支分析三种模式图像,三种模式融合成一个分支来组合信息。组合后分支由多个全连接层组成,并充当分类器。
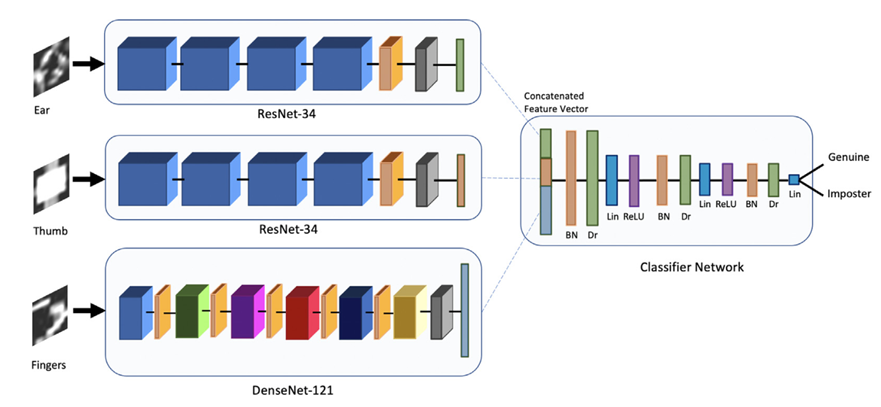
将手指、耳朵、拇指图像作为输入,并输出标签概率分布
- 耳朵和拇指图像使用 ResNet-34 架构,每个 ResNet-34stems 产生 512 元素特征向量
- 四指图像使用 DenseNet-121 stem,每个 DenseNet-121stems 产生1024 元素特征矢量
基准架构对比
端到端 CNN,单模态模型
仅使用一种模态图像耳朵、手指或图像,以端到端方式训练 CNN。最简单涉及 CNN 的 baseline 模型,输入是 10×10 灰度的身体部位图像,输出是对可能标签、真实用户和冒名顶替者的伯努利概率分数。
CNN 提取提取特征后用经典机器学习分类器,单模态模型
CNN 作为特征提取器, 要么在 Imagenet或类似大小数据集预训练,要么在更小数据集进行微调。这组模型使用 CNN 来利用其表示能力,并在提取的特征向量上训练各种经典机器学习算法。
首先按照端到端方式在每个模态上训练 CNN,从而产生能够以相当高的准确度执行用户认证的模型。用它作为特征提取器来训练一个梯度提升机器:XGBoost、RF、SVM
在排列中获得九个配置 {耳朵,四个手指,拇指} × {XGB,RF,SVM}
经典机器学习分类器,训练级联特征的多模态模型
将上述单模态模型,将单模态特征连接成一个包含所有三种模态信息的向量,这个组 合的特征向量然后被用于训练 XGB、RF 和 SVM
三种分类方法中的每一种都从三种模态获取输入,融合从单独微调的网络的全局平均池层中提取的特征,并输出指示用户是真实的还是冒名顶替者的概率分数
经过端到端、训练串联特征的多模态模型
类似于上述,区别在于这些模型中的级联特征向量通过多个全连接层,这些层具有交错的非线性 non-linearity,、丢失 dropout 和批量规范化层 batch normalization layers
经过端到端、训练的级联模态图像的多模态模型
接受一个组合图像作为输入,前面都是接受特征向量。图像包含来自三个水平连接的模态的三个图像。创建这个网络的目的是调查一个单一的网络是否可以有效地分析来自三种模态的图像,使用相同的表示空间。
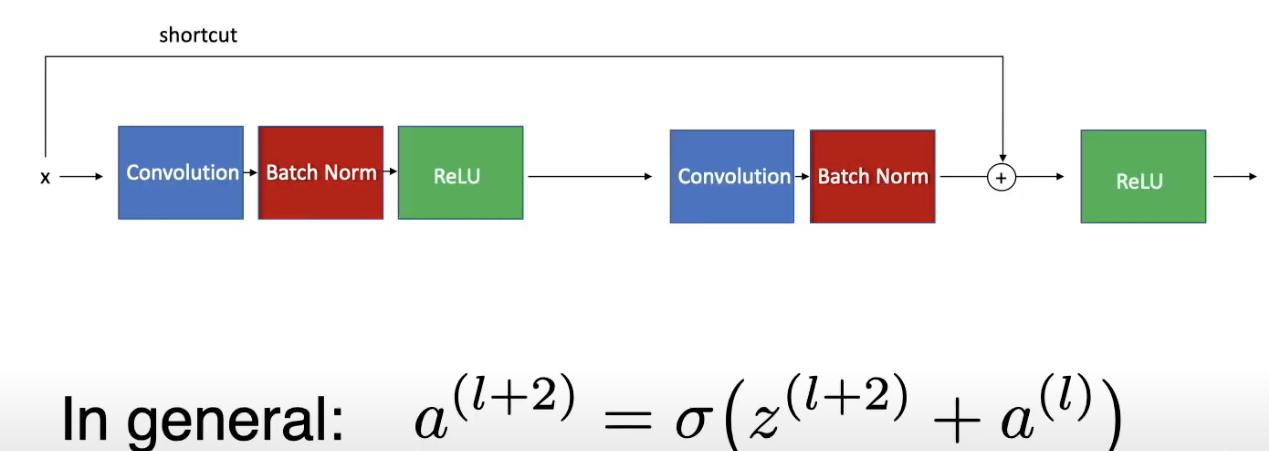
ResNet-34
ResNet 网络结构主要参考了 VGG19 网络,在其基础上通过短路连接加上了残差单元。ResNet 大多使用 3x3 的卷积核并且遵循以下两条设计原则:
- 对于同样输出特征图大小,每层拥有同样 filters
- 当特征图大小降低一半时,特征图数量增加一倍,以保持网络复杂度
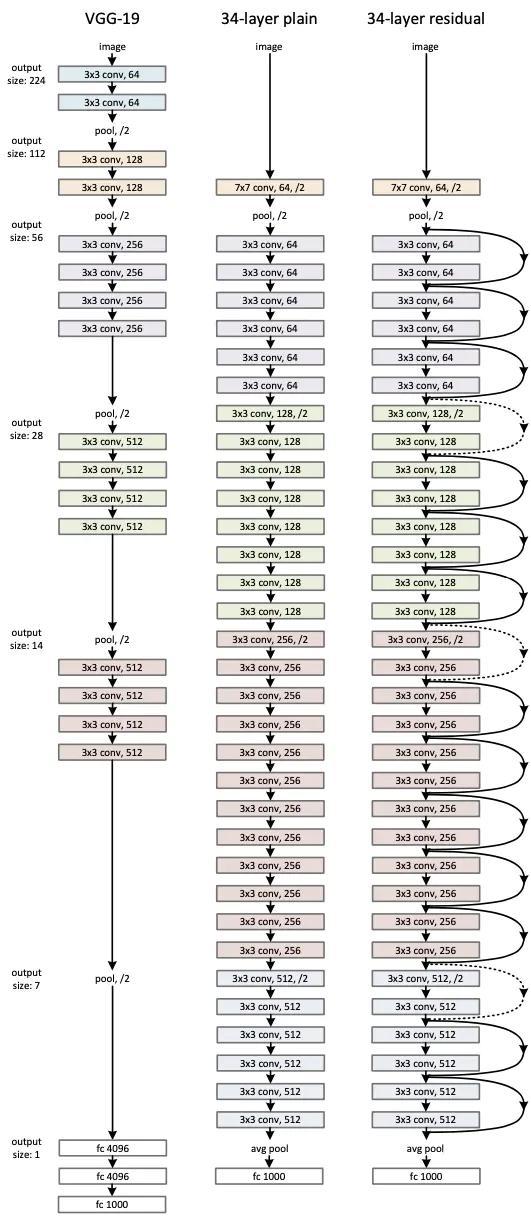
- VCG-19 网络
- 朴素 ResNet-34 网络
- 包含残差单元 ResNet-34 网络
ResNet-34 在普通网络每两层之间添加短路机制,形成残差学习。输入图像是 224x224,首先通过 1 个卷积层,接着通过 4 个残差层,最后通过 Softmax 之中输出一个 1000 维的向量,代表 ImageNet 的 1000 个分类。
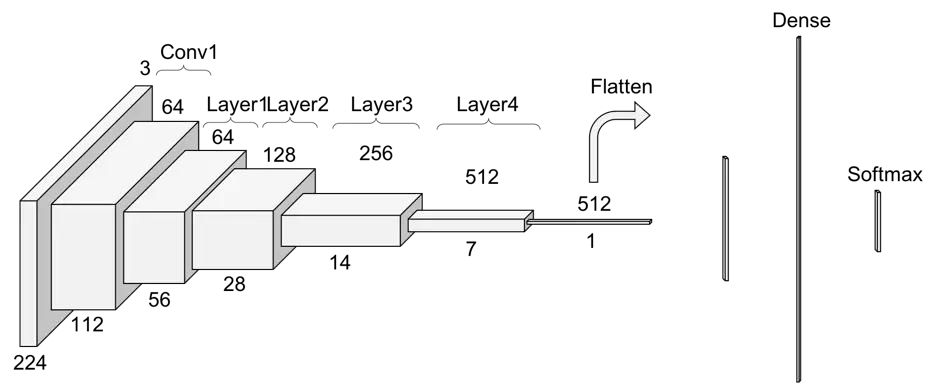
ResNet 克服了 “梯度消失 “问题,使得构建具有多达数千个卷积层的网络成为可能,其性能优于较浅的网络。使用对上一层的参考来计算某一层输出。
DenseNet-121
传统的 L 层卷积网络只有 $L$ 个连接,是指每一层只与后一层相连;一个 $L$ 层的 DenseNet 网络有 $\dfrac {L\left(L+1\right)}2$ 个连接,是指每一层都与后继所有层相连接
DenseNet 优势:
- 减缓梯度消失
- 加强特征传递
- 有效特征复用
- 减少参数数量
具体做法::两两连接网络中的所有层。每一层从它前面的所有层中获得了额外的输入,同时也将它自身输出的特征图传递到后续的所有层中
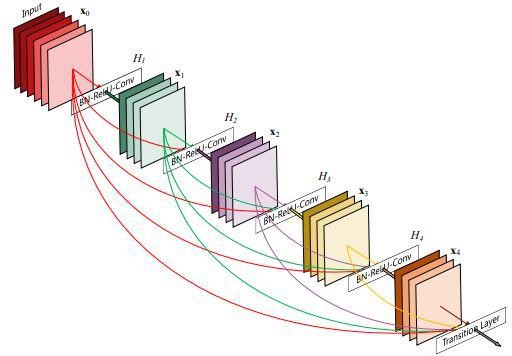
与 ResNet 相比,DenseNet 没有使用加和的方式去融合特征,而是选择了在通道层拼接的方式,即 DenseNet 第 m 层有 m 个输入特征图的组合,包含了从输入层到第 m-1 层一共 m 层的输出特征图。 然后第 m 层自身的输出特征图又传递到后续的L-m 的每一个层的输入当中
- DenseNet 网络需要的的参数更少
- DenseNet 改善了信息和梯度在网络中的流动,使得网络很容易训练
- 实验观测到 DenseNet 这种网络连接模式有正则化的功效,在小数据集上能够减少过拟合
实验
预处理
为了使分类器对噪声具有鲁棒性,实验在训练阶段应用了标准图像增强。实验应用了缩放、旋转、少量平移、中心裁剪,然后使用 Imagenet 数据集的平均值和标准偏差对每个图像进行标准化,这是一种常见的统计数据
实验实施
实现中使用了 PyTorch 和 FastAI 框架的组合。使用随机梯度下降算法Adam的变体,通过端到端地训练网络交叉熵损失,优化模型参数



