图
- $G=(V,E)$
- $V$——结点
- $E$——边
有向图 & 无向图
- $<u,v>$——有向图
- $(u,v)$——无向图
简单图 & 多重图
简单图:
- 无自回路
- 无重边
多重图:非简单图
完全图
图有最多的边
无向完全图:${\dfrac{n(n-1)}{2}}$条边
有向完全图:$n(n-1)$条边
子图
$\left. \begin{array}{r} V'\subseteq V\\ E'\subseteq E\\ \end{array} \right\} \Rightarrow G'\left( V',E' \right) \subseteq G\left( V,E \right) $生成子图:$V(G’)=V(G)$
连通 & 连通图 & 连通分量
连通:顶点间有路径存在
连通图:无向图任两个点之间连通
- 若边数$<n-1$,则必为非连通图
- 非连通图边数最多:由$n-1$个顶点构成完全图,边数$\le \dfrac{(n-1)(n-2)}2$
连通分量(极大连通子图):互相不连通的子图
- 连通图连通分量有且仅有自身,非连通图连通分量可能有多个
- 若加一个点,仍然连通,则非连通分量
强连通图 & 强连通分量
强连通图:有向图任意两点互通
- 强连通图最少边$\le n$,构成环路
- 强连通图:最多$n(n-1)$边
强连通分量:有向图极大连通子图
顶点的度
无向图$TD(v):$附着于顶点的边数
$\sum TD(v)=2e$
有向图:
- 入度$ID(v):$以顶点为终点的边数
- 出度$OD(v):$以顶点为起点的边数
$\sum ID(v)=\sum OD(v)=e$
路径
路径:顶点间连接
回路(环):起始点相同的路径
- 若边数$\ge n-1$,图一定有环
简单路径:顶点不重复出现的路径
网:带权路径图
稠密图 & 稀疏图
稠密图:$|E|\ge |V|\log|V|$
稀疏图:$|E|<|V|\log|V|$
生成树 & 生成森林
连通图包含全部顶点的一个极小连通子图
边数:$n-1$
去一边则为非连通图
加一边则形成回路
非连通图所有连通分量生成树
存储结构
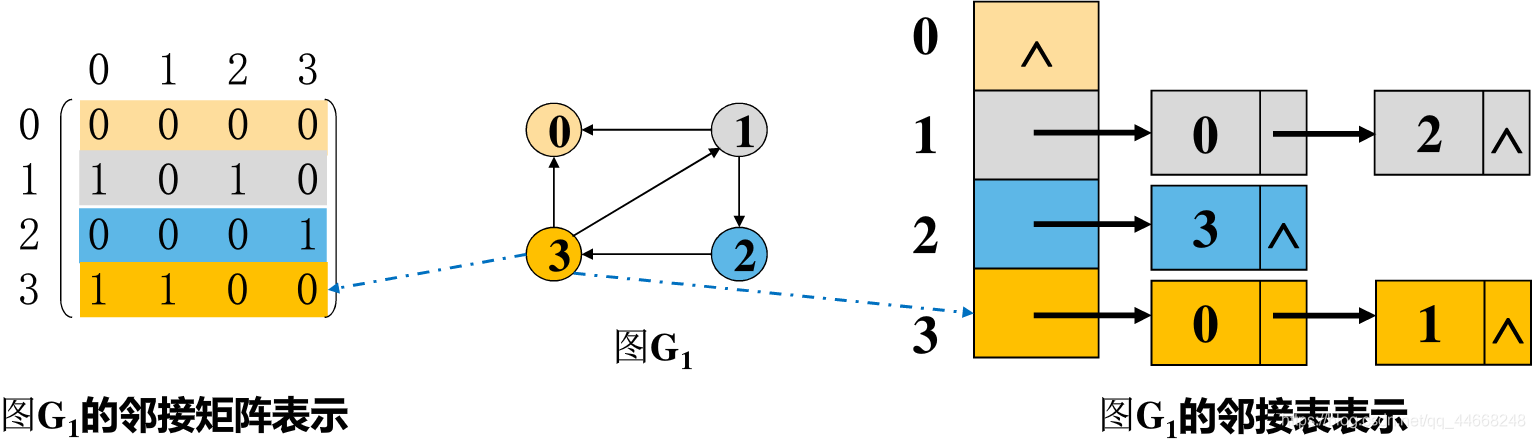
邻接矩阵
表现顶点之间相邻关系的矩阵
$G(u,v)$为图$ A[u][v]=\left\{ \begin{array}{lr} 1&若(u,v)或
$G(u,v)$为网$ A[u][v]=\left{ \begin{array}{lr} w_{ij}&若(u,v)或<u,v>\in{E} & \0&若u=v\{\infty} &否则 \end{array} \right. $
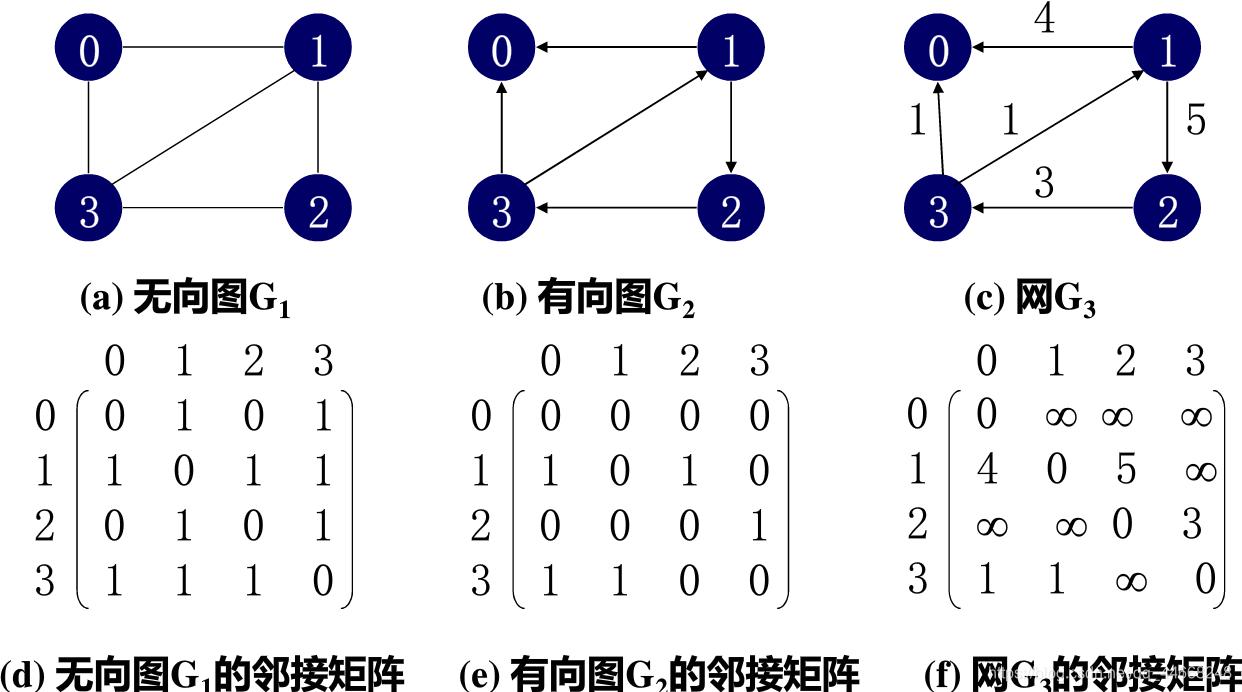
对于无向图,第$i$行非零元素个数为该点$i$的度$TD(v_i)$
有向图第$i$行非零元素个数为$i$的出度$OD(v_i)$
有向图第$j$列非零元素个数为$j$的入度$ID(v_j)$
对于带权图,$A^n$代表$i$到$j$的长度为$n$的路径的数目
适合稠密图
定义
typedef struct mGraph
{
ElemType **a;// 动态二维数组,用来存储邻接矩阵
int n; // 图中顶点数
int e; // 图中边数
ElemType noEdge; // 两顶点无边的值
}mGraph;优缺点
优点
便于判断两个顶点是否有边
适合稠密图
便于计算各个顶点度
对于无向图,第$i$行顶点之和即为顶点$i$的度
对于有向图,第$i$行顶点之和为顶点$i$的出度
第$i$行顶点之和为顶点$i$的入度
缺点
- 统计边的数目时间复杂度$O(n^2)$
- 空间复杂度$O(n^2)$
邻接表
- 用$n$个单链表代替邻接矩阵中的$n$行
- 每个顶点对应一个单链表
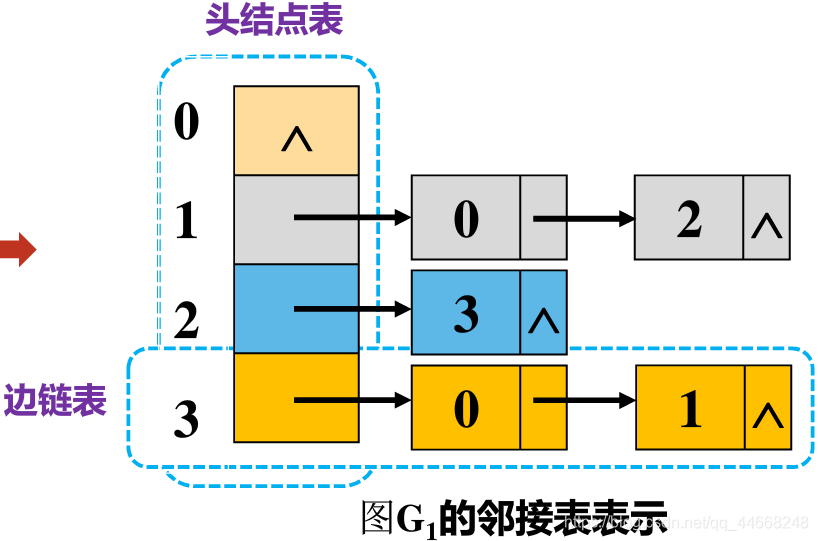
代码
边结点定义
typedef struct eNode // 边结点定义
{
int AdjVex; // 邻接点域
ElemType w; // 权重域
struct ENode* NextArc; // 指针域
}ENode;
typedef struct lGraph
{
ENode **a; // 指向一维指针数组
int n; // 顶点数
int e; // 边数
}LGraph;优缺点
优点
便于统计边数$O(n+e)$
查找某点邻边$O(n)$
无向图空间复杂度$O(n+2e)$
有向图空间复杂度$O(n+e)$
适合稀疏图
缺点
- 不便判断顶点之间是否有边$O(n)$
- 不便于计算各个顶点度
十字链表
有向图
弧结点
tailVex弧尾结点 | headVex 弧头结点 | hLink 指向弧头相同下一个结点 | tLink 指向弧尾相同下一个结点 | ifno 弧信息 |
顶点结点
| data 结点数据 | firstIn 结点为头的点 | firstOut 结点为尾的点 |
邻接多重表
无向图
边结点
| mark 标志域:标记该结点是否被搜索 | iVex 顶点位置 | iLink 下一个顶点iVex的边 | jVex 顶点位置 | jLink 下一个顶点jVex的边 | info 边信息 |
顶点结点
| data 数据域 | firstEdge 第一条依附于该点的边 |
图的遍历
深度优先搜索(DFS)
void DFS(int v, int visited[], LGraph g)
{
ENode *w;
printf("%d",v); // 访问顶点v
visited[v] = 1;
for(w = g.a[v] ; w ; w = w>nextArc)
if(!visited[w->adjVex])
DFS(w->adjVex, visited, g);
}void DFSTraverse(LGraph g)
{
int i; // 动态生成标记数组
int *visited = (int*)malloc(g.n*sizeof(int)); // 初始化标记数组
for(i=0 ; i < g.n ; i++) // 逐一检查每个顶点,若未被访问,则调用DFS
visited[i] = 0;
for(i=0 ; i < g.n ; i++)
if(!visited[i])
DFS(i, visited, g);
free(visited);
}时间复杂度
- 邻接表$O(n+e)$
- 邻接矩阵$O(n^2)$
空间复杂度
$O(n)$
邻接表$O(n+e)$
- 邻接矩阵$O(n^2)$
图的应用
最小代价生成树
边权值和最小
普利姆算法(Prim)
步骤
- 分为已选$U$与未选$V$
- 选择$U$和$V$之间最小值
- 重复直到选完所有点
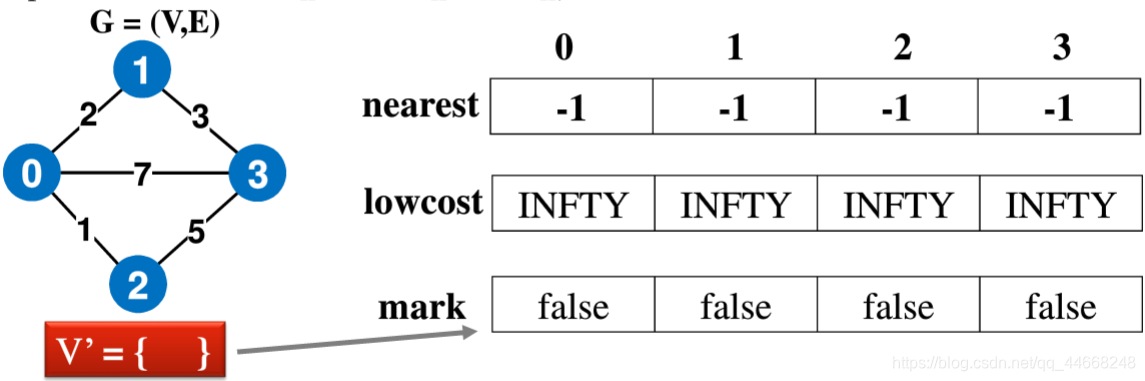
- nearst该点与未选择区域最近的点
- lowcost最短的距离
- mark是否已被选择
克鲁斯卡尔算法(Kruskal)
步骤
- 选择图中最短的边
- 若未形成回路,则继续选
- 形成了回路,再去选其他的
单源最短路径
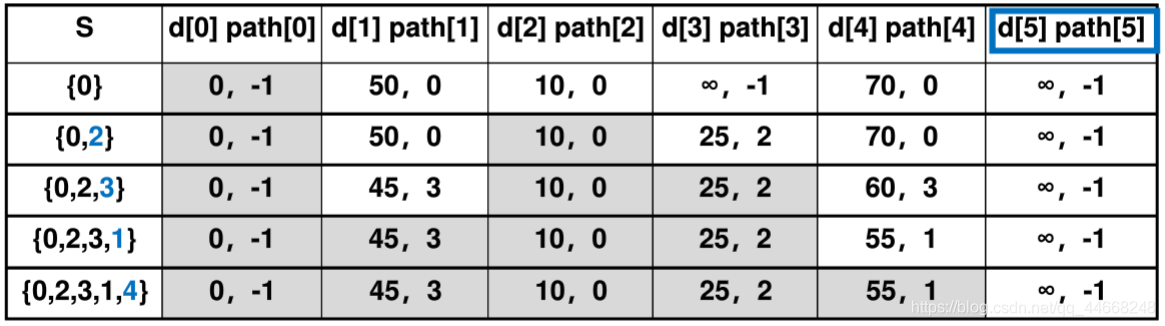
迪杰斯特拉算法
步骤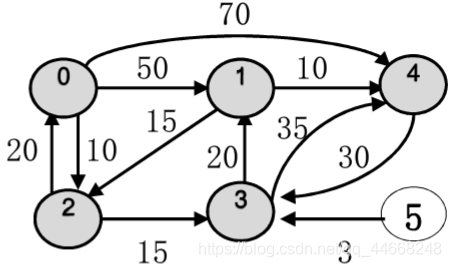
- 选已选点最短路径
- 更新${d,path}$
拓扑排序
- 具有先决条件的网络
- 从有向图中选择一个入度为0的顶点输出
- 删除上述顶点与其所有边
- 重复上述两步直到不存在入度为0的点
逆拓扑排序
- 从有向图中选择一个出度为0的顶点输出
- 删除上述顶点与其所有边
- 重复上述两步直到不存在出度为0的点
可用DFS完成逆拓扑排序
AOV网
有向边表示领先关系的有向无环图
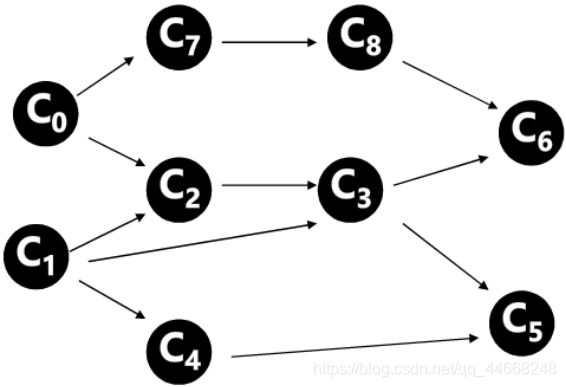
拓扑排序过程
过程
- 找到入度$0$的点
- 删除其所有边
- 重复
代码
计算各顶点入度
void Degree(int* inDegree, LGraph g)
{
int i;
ENode *p;
for(i=0 ; i < g.n ; i++) // 数组初始化
inDegree[i] = 0;
for(i=0 ; i < g.n ; i++)
for(p = g.a[i] ; p ; p = p->nextArc) // 检查顶点vi所有邻接点
inDegree[p->adjVex]++; // 邻接点入度+1
}拓扑排序
Status TopoSort(int* topo, LGraph g)
{
int i, j, k;
ENode *p;
Stack S;
int* inDegree = (int*)malloc(sizeof(int) * g.n);
Degree(inDegree, g); // 计算顶点入度
Create(&S, g.n); // 初始化栈堆
for(i=0 ; i < g.n ; i++)
if(!inDegree[i])
Push(&S, i); // 入度为0顶点入栈
while(!IsEmpty(&S)) // 若栈S不空
{
Top(&S, &i); Pop(&S); //顶点v出栈
topo[m] = i; // 将v输出到拓扑回归序列中
m++; // 对输出顶点计数
for(p=g.a[i] ; p; p = p->nextArc) // 检查顶点vi所有邻接点
{
k = p->adjVex;
inDegree[K]--; // 入度为0邻接点进栈
}
}
if(m < g.n) // 若还有顶点为输出,则表明有环
return Error;
else
return OK;
}关键路径AOE
- 顶点:事件
- 边:活动
- 权重:活动开销
- 只有当同一关键路径数值减少时,才能缩短工期
参量
事件$v_k$最早发生时间$ve(k)$(选择最长的路径)
$ve(0)=0$
$ve(k)=\max{ve(j)+Weight(v_j, v_k)}$
事件$v_k$最迟发生时间$vl(k)$(逆拓扑,选择短的)
$vl(final)=ve(final)$
$vl(k)=\min{vl(j)-Weight(v_k,v_j) }$
活动$a_i$最早开始时间$e(i)$
起点最早时间$e(i)=ve(k)$
活动$a_i$最迟开始时间$l(i)$
终点最迟时间与活动时间差额$l(i)=vl(j)-Weight(v_k,v_j)$
活动最迟和最早开始时间差额$d(i)$
$d(i)=l(i)-e(i)$
关键活动$d(i)=0$



